In [1]:
Copied!
from river import preprocessing, metrics, datasets
from deep_river.anomaly import RollingAutoencoder
from torch import nn, manual_seed
import torch
from river import preprocessing, metrics, datasets
from deep_river.anomaly import RollingAutoencoder
from torch import nn, manual_seed
import torch
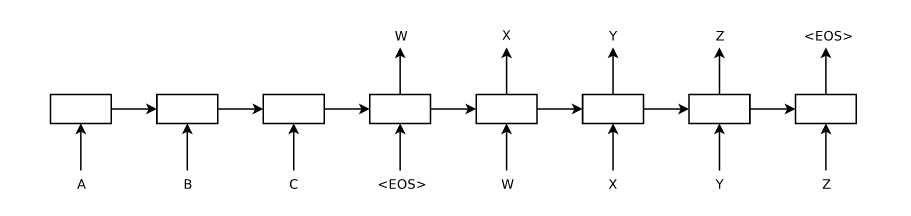
LSTM Encoder-Decoder architecture by Sutskever et al. 2014 (https://arxiv.org/abs/1409.3215). The decoder only gets access to its own prediction of the previous timestep. Decoding also takes performed backwards.
In [2]:
Copied!
class LSTMDecoder(nn.Module):
def __init__(
self,
input_size,
hidden_size,
sequence_length=None,
predict_backward=True,
num_layers=1,
):
super().__init__()
self.cell = nn.LSTMCell(input_size, hidden_size)
self.input_size = input_size
self.hidden_size = hidden_size
self.predict_backward = predict_backward
self.sequence_length = sequence_length
self.num_layers = num_layers
self.lstm = (
None
if num_layers <= 1
else nn.LSTM(
input_size=hidden_size,
hidden_size=hidden_size,
num_layers=num_layers - 1,
)
)
self.linear = (
None
if input_size == hidden_size
else nn.Linear(hidden_size, input_size)
)
def forward(self, h, sequence_length=None):
"""Computes the forward pass.
Parameters
----------
x:
Input of shape (batch_size, input_size)
Returns
-------
Tuple[torch.Tensor, Tuple[torch.Tensor, torch.Tensor]]
Decoder outputs (output, (h, c)) where output has the shape (sequence_length, batch_size, input_size).
"""
if sequence_length is None:
sequence_length = self.sequence_length
x_hat = torch.empty(sequence_length, h.shape[0], self.hidden_size)
for t in range(sequence_length):
if t == 0:
h, c = self.cell(h)
else:
input = h if self.linear is None else self.linear(h)
h, c = self.cell(input, (h, c))
t_predicted = -t if self.predict_backward else t
x_hat[t_predicted] = h
if self.lstm is not None:
x_hat = self.lstm(x_hat)
return x_hat, (h, c)
class LSTMAutoencoderSutskever(nn.Module):
def __init__(self, n_features, hidden_size=30, n_layers=1):
super().__init__()
self.n_features = n_features
self.hidden_size = hidden_size
self.n_layers = n_layers
self.encoder = nn.LSTM(
input_size=n_features, hidden_size=hidden_size, num_layers=n_layers
)
self.decoder = LSTMDecoder(
input_size=hidden_size,
hidden_size=n_features,
predict_backward=True,
)
def forward(self, x):
_, (h, _) = self.encoder(x)
x_hat, _ = self.decoder(h[-1], x.shape[0])
return x_hat
class LSTMDecoder(nn.Module):
def __init__(
self,
input_size,
hidden_size,
sequence_length=None,
predict_backward=True,
num_layers=1,
):
super().__init__()
self.cell = nn.LSTMCell(input_size, hidden_size)
self.input_size = input_size
self.hidden_size = hidden_size
self.predict_backward = predict_backward
self.sequence_length = sequence_length
self.num_layers = num_layers
self.lstm = (
None
if num_layers <= 1
else nn.LSTM(
input_size=hidden_size,
hidden_size=hidden_size,
num_layers=num_layers - 1,
)
)
self.linear = (
None
if input_size == hidden_size
else nn.Linear(hidden_size, input_size)
)
def forward(self, h, sequence_length=None):
"""Computes the forward pass.
Parameters
----------
x:
Input of shape (batch_size, input_size)
Returns
-------
Tuple[torch.Tensor, Tuple[torch.Tensor, torch.Tensor]]
Decoder outputs (output, (h, c)) where output has the shape (sequence_length, batch_size, input_size).
"""
if sequence_length is None:
sequence_length = self.sequence_length
x_hat = torch.empty(sequence_length, h.shape[0], self.hidden_size)
for t in range(sequence_length):
if t == 0:
h, c = self.cell(h)
else:
input = h if self.linear is None else self.linear(h)
h, c = self.cell(input, (h, c))
t_predicted = -t if self.predict_backward else t
x_hat[t_predicted] = h
if self.lstm is not None:
x_hat = self.lstm(x_hat)
return x_hat, (h, c)
class LSTMAutoencoderSutskever(nn.Module):
def __init__(self, n_features, hidden_size=30, n_layers=1):
super().__init__()
self.n_features = n_features
self.hidden_size = hidden_size
self.n_layers = n_layers
self.encoder = nn.LSTM(
input_size=n_features, hidden_size=hidden_size, num_layers=n_layers
)
self.decoder = LSTMDecoder(
input_size=hidden_size,
hidden_size=n_features,
predict_backward=True,
)
def forward(self, x):
_, (h, _) = self.encoder(x)
x_hat, _ = self.decoder(h[-1], x.shape[0])
return x_hat
Testing¶
The models can be tested with the code in the following cells. Since River currently does not feature any anomaly detection datasets with temporal dependencies, the results should be expected to be somewhat inaccurate.
In [3]:
Copied!
_ = manual_seed(42)
dataset = datasets.CreditCard().take(5000)
metric = metrics.RollingROCAUC(window_size=5000)
module = LSTMAutoencoderSutskever(30) # Set this variable to your architecture of choice
ae = RollingAutoencoder(module=module, lr=0.005)
scaler = preprocessing.StandardScaler()
_ = manual_seed(42)
dataset = datasets.CreditCard().take(5000)
metric = metrics.RollingROCAUC(window_size=5000)
module = LSTMAutoencoderSutskever(30) # Set this variable to your architecture of choice
ae = RollingAutoencoder(module=module, lr=0.005)
scaler = preprocessing.StandardScaler()
In [4]:
Copied!
for x, y in list(dataset):
scaler.learn_one(x)
x = scaler.transform_one(x)
score = ae.score_one(x)
metric.update(y_true=y, y_pred=score)
ae.learn_one(x=x, y=None)
print(f"ROCAUC: {metric.get():.4f}")
for x, y in list(dataset):
scaler.learn_one(x)
x = scaler.transform_one(x)
score = ae.score_one(x)
metric.update(y_true=y, y_pred=score)
ae.learn_one(x=x, y=None)
print(f"ROCAUC: {metric.get():.4f}")
ROCAUC: 0.6839
In [ ]:
Copied!